2.2.1 KDD*▀^│╠─Żą═
╗∙ė┌ļpÄņģf═¼ÖCųŲĄ─KDD*ĮYśŗ─Żą═ė├ė┌╠Ä└ĒĮYśŗ╗»öĄō■═┌Š“å¢Ņ}Ż¼╦³ģ^äeė┌╣╠ėąĄ─KDD─Żą═ĪŻį┌šōūC┴╦öĄō■ūėŅÉĮYśŗĄ─┐╔▀_ĘČ«Ā┼c═┌Š“ų¬ūRÄņĄ─═Ų└ĒĘČ«Āų«ķgĄ─Ą╚ārĻPŽĄĄ─╗∙ĄA╔ŽŻ¼╦³═©▀^åó░lą═ģfš{Ų„Å─ų¬ūRÄņųą░l¼Fų¬ūRČ╠╚▒Ż¼åóäė═┌Š“▀M│╠╩╣ÖCŲ„ūį╔Ēų„äėŠ█Į╣Ż¼Ą├ĄĮ╝┘įOęÄätŻ╗▓ó═©▀^ŠSūoą═ģfš{Ų„īŹĢrĄžĄĮų¬ūRÄņųąī”æ¬╬╗ų├▓ķšęųžÅ═Īó╚▀ėÓĪó├¼Č▄Ą╚Ūķør▀Mąąų¬ūRÄņĄ─īŹĢrŠSūoĪŻįōĒŚā╚╚▌ęč½@ć°╝ę░l├„īŻ└¹ĪČę╗ĘN╗∙ė┌ļpÄņģf═¼ÖCųŲĄ─KDD*ĘĮĘ©╝░ŽĄĮyĪĘŻ©ZL 01145080.0Ż®Ż©ęŖĖĮ╝■ Ż®ĪŻ
Ž┬├µ═©▀^KDD*ĮYśŗ─Żą═┼cĮøĄõĄ─KDDĮYśŗ─Żą═Ą─ī”▒╚ū÷Ąõą═šf├„Ż║
KDDĮYśŗ─Żą═ų╝į┌×ķKDD╠ß╣®║Ļė^ųĖī¦║═╣ż│╠╗»ĘĮĘ©ĪŻ─┐Ū░Ż¼ć°ā╚═ŌīWš▀ęč╠ß│÷┴╦╚¶Ė╔─Żą═Ż¼╚ńBrachmanĄ╚ė┌1996─Ļ╠ß│÷ę╗ĘNīŹė├Ą─KDD▀^│╠ęĢłDŻ¼įōęĢłDÅŖš{Ą─╩Ū▀^│╠Ą─Į╗╗źąįŻ╗NCRĪóSPSSĪóDaimlerChrysler║═OHRAė┌1997─Ļķ_╩╝┴╦KDDĮYśŗ─Żą═╣żśIś╦£╩Ą─ųŲČ©╣żū„Ż¼▓óį┌1999─Ļ═Ų│÷┴╦CRISP-DMĄ─KDDĮYśŗ─Żą═╣żśIś╦£╩Ą─1.0░µĪŻ▀@ŲõųąŻ¼FayyadĄ╚╠ß│÷Ą─ČÓļAČ╬─Żą═ęįŲõ═©ė├ąįČ°▒╗ÅVĘ║Įė╩▄ĪŻ▀@ę╗─Żą═╚ńłD4╦∙╩ŠŻ║
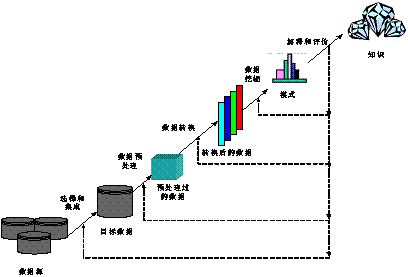
łD4 FayyadĄ╚╠ß│÷Ą─ĮøĄõĄ─KDDĮYśŗ─Żą═
╗∙ė┌ļpÄņģf═¼įŁ└ĒŻ©ÖCųŲŻ®Ż¼╬ęéā╠ß│÷┴╦╚½ą┬Ą─KDD*ĮYśŗ─Żą═Ż¼Ųõ┐é¾wĮYśŗ╚ńłD5╦∙╩ŠŻ║
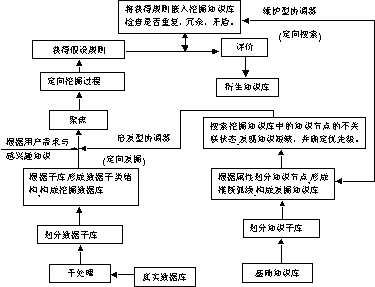
łD5 KDD*ŽĄĮy┐é¾wĮYśŗłD
┼cFayyadĄ╚╠ß│÷Ą─ĮYśŗ─Żą═ŽÓ▒╚Ż¼KDD*ėą╚ńŽ┬╠žš„Ż║
1) KDD*ėąÖCĄž£Ž═©┼c╚┌║Ž┴╦KDD*ą┬░l¼FĄ─ų¬ūR┼c╗∙ĄAų¬ūRÄņųą╣╠ėąĄ─ų¬ūRŻ¼╩╣╦³éā│╔×ķę╗éĆėąÖCĄ─š¹¾wŻ╗╝┤īŹ¼F┴╦Ī░ė├æ¶Ą─Ž╚“×ų¬ūR┼cŽ╚Ū░░l¼FĄ─ų¬ūR┐╔ęį±Ņ║ŽĄĮ░l¼F▀^│╠ųąĪ▒ĪŻ
2) į┌ų¬ūR░l¼F▀^│╠ųąŻ¼KDD*ī”ė┌╚▀ėÓąįĄ─ĪóųžÅ═ąįĄ─Īó▓╗ŽÓ╚▌Ą─ą┼Žóū÷│÷┴╦īŹĢr╠Ä└ĒŻ©╝┤ų¬ūRÄņĄ─īŹĢrŠSūoŻ®Ż¼ėąą¦Ąž£p╔┘┴╦ė╔ė┌▀^│╠Ęe└█Č°įņ│╔Ą─å¢Ņ}Ą─Å═ļsąįŻ¼═¼Ģr×ķą┬┼fų¬ūRĄ─╚┌║Ž┼c║Ž│╔╠ß╣®┴╦Ž╚øQŚl╝■Ż╗īŹ¼F┴╦Ī░ų¬ūR┼cöĄō■Äņ═¼▓Į▀M╗»Ī▒ĪŻ
3) KDD*Ė─ūā┼cā×╗»┴╦ų¬ūR░l¼FĄ─▀^│╠┼c▀\ąąÖCųŲŻ¼īŹ¼F┴╦Ī░ČÓį┤Ņ^Ī▒Š█Į╣┼c£p╔┘įuār┴┐ĪŻ
4) KDD*ÅŖ╗»┴╦ų¬ūR░l¼FĄ─ųŪ─▄╗»│╠Č╚Ż¼╠ßĖ▀┴╦šJų¬ūįų„ąįŻ©▀@īó╩ŪĮ±║¾ŽÓ«öķLĄ─ę╗ļAČ╬ā╚▒Ż│ųĄ─蹊┐╗∙š{Ż®,▌^ėąą¦Ąž┐╦Ę■ŅIė“īŻ╝ęĄ─ūį╔ĒŠųŽ▐ąįŻ¼īŹ¼F┴╦Ī░▓╔ė├ŅIė“ų¬ūR▌oų·│§╩╝░l¼FĄ─Š█Į╣Ī▒ĪŻ
5) ū„×ķKDD*Ą─║╦ą─╝╝ągĪ¬ļpÄņģf═¼ÖCųŲĄ─蹊┐Ż¼Įę╩Š┴╦į┌ų¬ūR░l¼F▀^│╠ųąŻ¼į┌ę╗Č©Ą─Į©ÄņįŁätŽ┬Ż¼ų¬ūRÄņ┼cöĄō■ÄņķgĄ─ī”æ¬ĻPŽĄŻ╗×ķīŹ¼FĪ░Ž▐ųŲąįĄ─╦č╦„Ī▒Č°£pąĪ╦č╦„┐šķgĪó╠ßĖ▀░lŠ“ą¦┬╩╠ß╣®┴╦ėąą¦Ą─╝╝ągĘĮĘ©ĪŻ
╔Žę╗Ēō [1] [2] [3] [4] [5] [6] [7] [8] [9] [10] [11] [12] [13] [14] [15] [16] [17] [18] [19] [20] [21] [22] [23] Ž┬ę╗Ēō
|